With some colleagues of Codit, we’re working on a huge messaging platform between organizations, which is built on top of Microsoft BizTalk Server. One of the key features we must deliver is reliable messaging. Therefor we apply AS4 as a standardized messaging protocol. Read more about it here. We use the AS4 pull message exchange pattern to send the messages to the receiving organization. Within this pattern, the receiving party sends a request to the AS4 web service and the messaging platform returns the first available message from the organizations inbox.
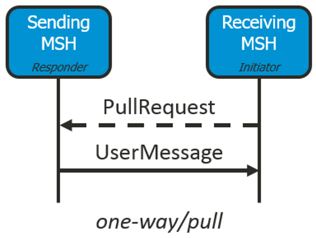
Initial Setup
Store Messages
In order to support this pattern, the messages must be stored in a durable way. After some analysis and prototyping, we decided to use SQL Server for this message storage. With the FILESTREAM feature enabled, we are able to store the potential large message payloads on disk within one SQL transaction.

(1) The messages are stored in the SQL Server inbox table, using a BizTalk send port configured with the WCF-SQL adapter. The message metadata is saved in the table itself, the message payload gets stored on disk within the same transaction via FILESTREAM.
Retrieve Messages
As the BizTalk web service that is responsible for returning the messages will be used in high throughput scenarios, a design was created with only one pub/sub to the BizTalk MessageBox. This choice was made in order to reduce the web service latency and the load on the BizTalk database. 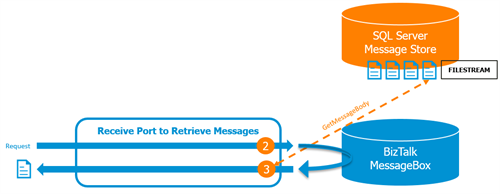
These are the two main steps:
(2) The request for a message is received and validated on the WCF receive port. The required properties are set to get the request published on the MessageBox and immediately returned to the send pipeline of the receive port. Read here how to achieve this.
(3) A database lookup with the extracted organization ID returns the message properties of the first available message. The message payload is streamed from disk into the send pipeline. This avoids that a potential large message gets published on the MessageBox. The message is returned via this way to the receiving party. In case there’s no message available in the inbox table, a warning is returned.
Potential Bottleneck
The pull pattern puts a lot of additional load on BizTalk, because many organizations (+100) will be pulling for new messages within regular time intervals (e.g. each 2 seconds). Each pull request is getting published on the BizTalk MessageBox, which causes extra overhead. As these pull requests will often result in a warning that indicates there’s no message in the inbox, we need to find a way to avoid overwhelming BizTalk with such requests.
Need for Caching
After some analysis, it became clear that caching is the way to go. Within the cache, we can keep track of the fact whether a certain organization has new messages in its inbox or not. In case there are no messages in the inbox, we need to find a way to bypass BizTalk and return immediately a warning. In case there are messages available in the organization’s inbox, we just continue the normal processing as described above. In order to select the right caching software, we listed the main requirements:
- Distributed: there must be the ability to share the cache across multiple servers
- Fast: the cache must provide fast response times to improve message throughput
- Easy to use: preferably simple installation and configuration procedures
- .NET compatible: we must be able to extend BizTalk to update and query the cache
It became clear that redis meets our requirements perfectly:
- Distributed: it’s an out-of-process cache with support for master-slave replication
- Fast: it’s an in-memory cache, which ensures fast response times
- Easy to use: simple “next-next-next” installation and easy configuration
- .NET compatible: there’s a great .NET library that is used on Stack Overflow
Implement Caching
To ease the implementation and to be able to reuse connections to the cache we have created our own RedisCacheClient. This client has 2 connection strings: one to the master (write operations), and one to the client (read operations). You can find the full implementation on the Codit GitHub. The redis cache is implemented in a key/value way. The key contains the OrganizationId, the value contains a Boolean that indicates whether there are messages in the inbox or not. Implementing the cache, is done on three levels:

(A) In case a warning is returned that indicates there’s no message in the inbox, the cache gets updated to reflect the fact that there is no message available for that particular OrganizationId. The key/value pair gets also a time-to-live assigned.
(B) In case a message is placed on the queue for a specific organization, the cache gets updated to reflect the fact that there are messages available for that particular OrganizationId. This ensures that the key/value pair is updated as new messages arrive. This is faster than waiting for the time-to-live to expire.
(C) When a new request arrives, it is intercepted by a custom WCF IOperationInvoker. Within this WCF extensibility, the cache is queried with the OrganizationId. In case there are messages in the inbox, the IOperationInvoker behaves as a pass-through component. In case the inbox of the organization is empty, the IOperationInvoker bypasses the BizTalk engine and immediately returns the warning. This avoids the request to be published on the message box. Below there’s the main part of the IOperationInvoker, make sure you check the complete implementation on Github.
Results
After implementing this caching solution, we have seen a significant performance increase of our overall solution. Without caching, response times for requests on empty inboxes were on average 1,3 seconds for 150 concurrent users. With caching, response times decreased until an average of 200 ms.
Lessons Learned
Thanks to the good results, we introduced redis cache on other functionality in our solution. We use it for caching configuration data, routing information and validation information. During the implementation, we encountered some lessons learned:
- Redis is a key/value cache, change your mindset to use it to the maximum.
- Re-use connections to the cache, as this is the most costly operation.
- Avoid serialization of cached objects.
Thanks for reading!
Jonathan & Toon
Subscribe to our RSS feed