At Codit, we are regularly engaged in customer IoT projects. By nature, IoT projects generate vasts amounts of data that need to be quickly ingested and stored. So with this in mind, I wanted to test how CosmosDb behaves when it needs to ingests large batches of historical observations.
The data set
To run the experiment, I used the historical flight data available here. The data model includes about 110 columns, out of which I picked the first 50 columns. I got about 5Gb of data comprised of millions of these rows. Each row is about 1725 bytes in size.
The CosmosDb setup
Since the experiment data is tabular in nature, I created a Table API database with one collection called flights.
Next, I wrote a C# program that would read the csv files from the dataset (each one is about 200Mb) and created a TableEntity using the DynamicTableEntity approach. I then grouped all rows based on their airport’s IATA code, which I decided to use as the PartitionKey for this experiment. Finally, the program creates insert batches of length 100 for every group of rows belonging to the same airport code. The program then takes each of these insertion batches (remember, each batch has up to 100 rows to insert) and executes them sequentially.
To reduce network latency, I provisioned an Azure VM in the same region as the CosmosDb (North Europe) and gave it a generous amount of RAM (12Gb) so it could load all the data set in memory (the program I wrote is not optimized to reduce memory consumption).
The result
- Overall, the program created 19005 insert batches, most of them holding 100 rows to insert.
- The program managed to execute 4–5 batches per second. This means it managed to insert about 400–500 rows/s. This is about 860KB/s throughput.
- The 96th percentile for batch insertion time (remember, we are talking about insertion of a batch that includes 100 rows, not about inserting individual rows) was 283ms.
Takeaway
With this experiment, I managed to hit 429 errors very quickly. At the end, I needed to increase the RU/s to 10’000. But most importantly, I needed to change the indexing policy from consistent to lazy. With the amount of data I was trying to load, I was not able to avoid 429 errors (RequestTooLarge) with a consistent indexing policy, not even when using 10’000 RU/s.
Write performance is excellent, as you can see from the result above. Even when using consistent indexing policy, the write performance of the batches was very high (when you don’t get throttled).
As typical for a v1 product, there are some inconsistencies between the service documentation and the actual APIs. For example, the documentation states that CosmosDb is not limited to the 100 rows/insert batch as Azure Table storage is. However, when building insertion batches with more than 100 entities, the program throws an exception: The maximum number of operations allowed in one batch has been exceeded, even though I am using the new WindowsAzure.Storage-PremiumTable library. I guess this new library is not updated. I did not try to insert batches using the REST API directly (the documentation only talks about working with .NET, there is no REST reference for the TableDB API).
I think the key takeaway for me is that, when designing a large-scale system with CosmosDb, you will have to be extremely diligent on calculating how much capacity the system will need to offer, and its corresponding cost trade-off. Getting large write throughput on this database seems to be expensive. On the other hands, I ran the same loading job against the traditional Azure Table Storage service, and I never got throttled at all. In summary, I can derive the following learnings:
- The performance of individual writes of CosmosDb is excellent.
- Getting high write throughput with consistent indexing is significantly more expensive on CosmosDb than Table Storage. Table Storage will give you way more throughput for less money.
- You should carefully optimize your CosmosDb index. Although the database advertises that everything is indexed by default (which is a great engineering feat, no question about it), the overhead of indexing everything is going to cost you money, especially if your data model is large.
- CosmosDb Table API effectively supports secondary indexes, whereas Table Storage only supports PartitionKey-RowKey indexing. This is a big advantage for CosmosDb when you need to run more complex queries.
Update
With some time in my hands, I refactored the code to execute the insert batches in parallel and do a more detailed write throughput comparison with the standard Azure Table Storage Table. In the refactoring I also decided to pick only 20 columns of the data set, and deserialize them a proper class to get the correct data types (instead of having them all as string). The conclusions don’t change, but I can offer now additional hard facts.
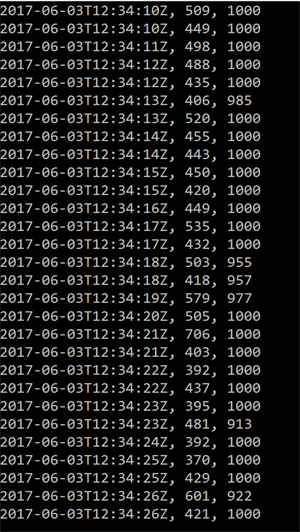
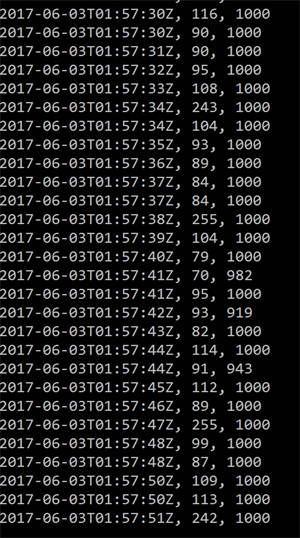
In the following screenshots, you’ll see rows with three values: the first value is the timestamp of the row insertion batch (remember, each batch contains up to 100 rows), the second value is the ellapsed time for inserting the batches in milliseconds, and the last value is the total amount of rows inserted.
Azure Table storage, 10 parallel batches of 100 rows per batch
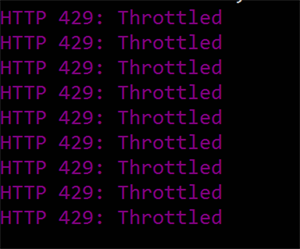
CosmosDb, 10 parallel insert batches of 100 rows per batch, consistent indexing, 10KRU/s. Basically useless, no request succeeds
CosmosDb, 10 parallel batches of 100 rows per batch, lazy indexing, 5K RU/s
You can see that the write performance of CosmosDb is much better than that of Azure Table storage (just compare the batches with 1000 records, many of them hover around 100ms). That is, when you don’t get throttled.
Subscribe to our RSS feed