Over the past couple of years, I’ve been actively working with customers that were using Azure Functions and/or Kubernetes to run their applications. As with everything, they both have their place in the cloud landscape and shine at particular aspects.
One aspect where they are different from each other is how your applications scale. With Azure Functions, you write code which is triggered when a certain trigger occurs and they handle the scaling for you, but you have no control over it. While with Kubernetes you have to tell it how to scale your application so it’s fully up to you!
On May 6th, 2019 Microsoft announced that they have partnered with Red Hat to build Kubernetes-based event-driven autoscaling (KEDA) which brings both worlds closer together.
![]()
I’ve had the honor to work with the KEDA folks to evolve the technology and define the path to go forward.
Today we’ll have a look at what KEDA is and in a next post, we’ll go through a .NET Core demo.
What is Kubernetes-based event-driven autoscaling (KEDA)
KEDA provides an autoscaling infrastructure that allows you to very easily autoscale your applications based on your criteria. Nothing to process? No problem, KEDA will scale your app back to 0 instances unless there is work to do.
As an application operator, you can deploy ScaledObject resources in your cluster which define the scaling rules for your application based on a given trigger.
These triggers are also referred to as “Scalers”. They provide a catalog of supported sources on which you can autoscale and provide the required custom metric feeds to scale on. This allows KEDA to very easily support new scale sources by adding an individual scaler for that service.
What is great about it is that it is not specific to one cloud vendor but you can basically run it on every Kubernetes cluster hosted anywhere.
My initial reaction was “how does this relate to Kubernetes Horizontal Pod Autoscalers? Why not just use that? Well, it actually builds on top of HPAs. Let’s have a closer look.
How does KEDA work?
KEDA comes with a set of core components to provide the scaling infrastructure:
- A Controller to coordinate all the work and watch for new
ScaledObjects - A Kubernetes Custom Metric Server
- A set of scalers which allow you to scale on external services
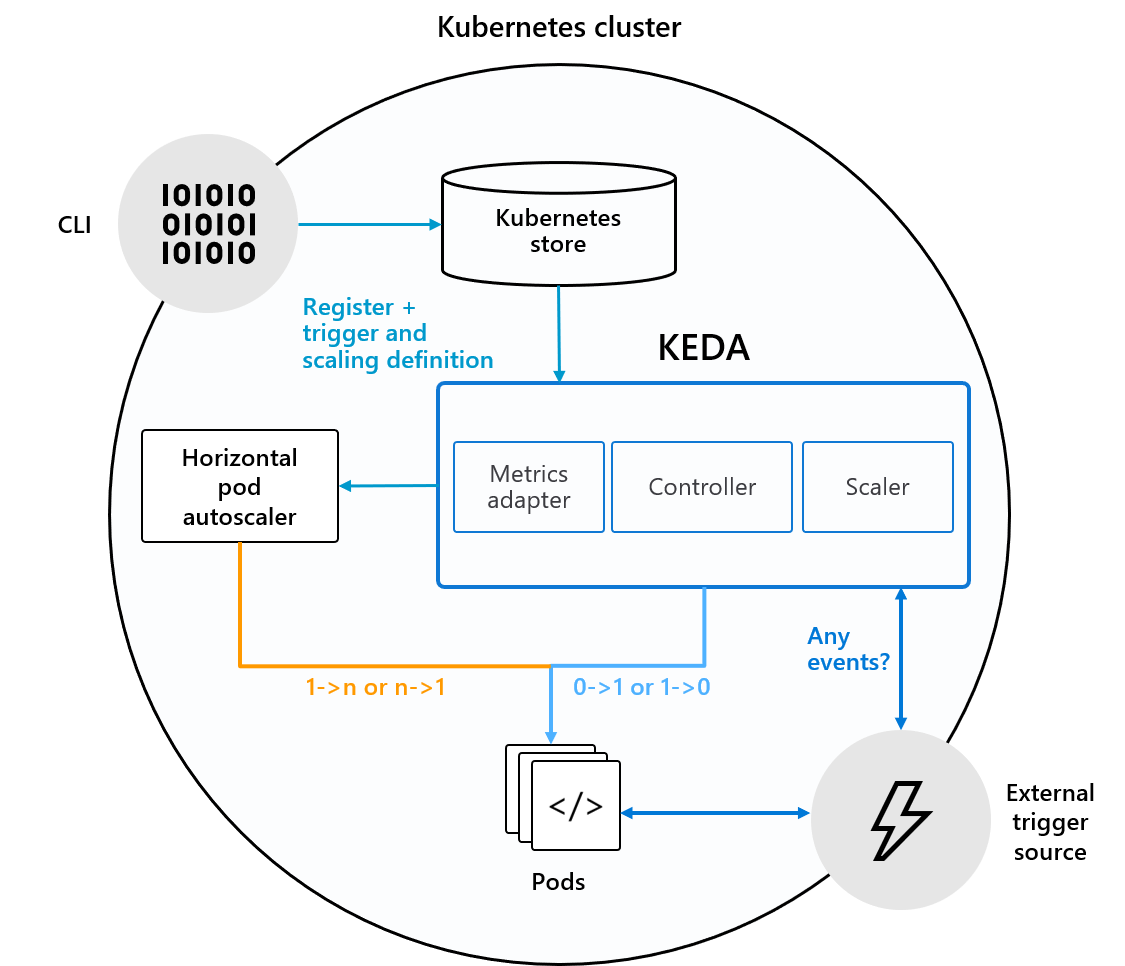
The controller is the heart of KEDA and is responsible for the two aspects:
- Watching for new ScaledObjects
- Ensuring that deployments where no events occur, scale back to 0 nodes. Once events occur, it makes sure that it scales from 0 to n.
The controller itself is in charge of scaling the deployment from 0 to 1 instance or vice versa, but scaling from 1 to n instances is handled by using a Kubernetes Horizontal Pod Autoscaler. This will be automatically created by the controller once it scales it to 1 instance due to events that are occurring and the HPA will consume the custom metric server to determine if it should scale out further.
The heavy lifting is done by the scalers which are defined as triggers in every ScaledObject. They define what external resources should be monitored and will report metrics back to the custom metric server so that the HPAs can consume them.
You can find a full overview of the ScaledObject specification and the supported triggers in the KEDA wiki.
Service Bus ScaledObject Example
Let’s have a look at a ScaledObject that automatically scales based on Service Bus Queue depth.
This will create a ScaledObject called order-processor-scaler which will automatically scale the order-processor Kubernetes Deployment which is defined via scaleTargetRef.deploymentName.
Next to that, we define that we want to use the azure-servicebus scale trigger and that we’d like to scale out if there are 5 or more messages in the orders queue. In order to avoid impacting other apps in the cluster, we define a maximum of 10 concurrent replicas via maxReplicaCount.
KEDA will use the KEDA_SERVICEBUS_QUEUE_CONNECTIONSTRING environment variable on our order-processor deployment to connect to Azure Service Bus and determine if the scaling criteria have met. This allows us to avoid duplication of configuration.
That’s it! All the rest is handled by KEDA for you!
Note – If we were to use a sidecar, we would need to define containerName which contains this environment variable.
KEDA supports Azure Functions, but it’s more than that!
One of the main concerns I’ve had with Azure Functions is the buy-in to the Azure Functions approach and the lock-in it has to Microsoft Azure. If customers start with Azure Functions, it’s hard to move that same workload to another service if we need higher control.
I was very thrilled when Microsoft announced that you can run your functions inside a Docker container! This allows you to run and deploy the same Azure Functions you ran locally in a container and run it on Azure or wherever you want! However, it’s not perfect given only Azure Functions will know how to scale it out for you. If you run it elsewhere it’s fully up to you to handle that – Enter KEDA!
The Azure Function Core Tool now allows you to take the same functions you already have and automatically scale them by using KEDA, without having to write your own ScaledObjects.
I have not tried this myself, but in theory, you can also define the scaling rules yourself for your own container if you are deploying a ScaledObject along with it.
This nice integration is a step forward to reduce the vendor lock-in of Azure Functions. This allows you to start by running it in Azure Functions as a FaaS/PaaS and move the workload to Kubernetes with KEDA installed as your application grows and you need the control.
Unfortunately, my feeling about running container-based functions in Azure Functions is that it’s not there yet. After deployment, the function was running perfectly, but I did not have the same monitor & manage experience as I do with code-based Functions – That’s the sweet spot to which it will eventually evolve, I hope.
My bet is that the issue lies in the fact that given it runs as a container, they cannot discover what functions are inside of it. Would it be an issue for me if they expose some sort of “function discovery endpoint” in the container? Not for me and I think that would make sense, but can have implications of course, but I think this is the path forward.
But for what it’s fair, I just did a small POC on Azure Functions so it might just be me.
The Azure Function Base image is openly available on Docker Hub and is available on GitHub.
Is this really event-based autoscaling?
Coming from the metric-based autoscaling & Promitor world this feels mostly similar, scalers are checking external services for input and report them accordingly. At first, it felt to me as KEDA was just another custom metric provider with Azure Function support on top of it. However, it’s more than that!
When using Azure Functions, the Core Tools handle all the scaling for you so from a customer perspective this is truly event-driven programming. Another aspect is the scale-to-zero which will scale up again in the event of work popping up in the queue with Azure Functions that makes the difference here.
Next to that, KEDA already supports autoscaling HTTP workloads by using Osiris which implicitly means it supports CloudEvents as well!
Last but not least, a scaler for Kubernetes Events is coming as well which makes it more interesting.
So it is event-driven autoscaling with some metrics pulling on the side, but what’s in a name!
Is the Azure Kubernetes Metrics Adapter dead?
Does this mean that James Sturtevant his Azure Kubernetes Metrics Adapter, which pulls in Azure Monitor metrics and expose them via a custom metrics server, is dead? No, I hope not.
It feels like both have their place in the Kubernetes scaling ecosystem where KEDA is great if you want to have the abstraction on top of Kubernetes, but if I want to control the HPAs that are being used I think the Azure Kubernetes Metrics Adapter is still a good tool in my belt.
They are just a different layer in terms of control and simplicity. To a certain degree, it feels like KEDA is more of developer-focused where they handle all the scaling themselves, while the Azure Adapter feels like it will still be used by (cluster) operators that do the autoscaling for the developers.
They know the ins and out of Kubernetes, they know what they are doing and want to have full control.
What’s coming?
There is a bunch of stuff that is on its way!
Currently, we have plans to add:
- CLI support to simplify how you can interact with
ScaledObjects, see scalers, etc. (#173) - A VS Code extensions provide a visual approach of interacting with KEDA. This would ideally be built on top of the CLI (#249)
- A dashboard to monitor and operate KEDA (#167)
- More scalers (scaler issues)
What would I like to see?
I would personally love to see KEDA supporting Pod AAD Identity (#). This allows Azure customers to assign an Azure AD identity to KEDA so that the Azure scalers can authenticate via Azure AD rather than via secrets which need to be maintained.
I would also love to see some nice integration between Azure Portal & KEDA where it would allow me to manage/monitor both my Cloud & Kuberenetes Functions. This would allow me to have one central overview of all Functions in my infrastructure.
However, given the scope of KEDA this should be leveraged by an Azure Function KEDA Agent of some sort which I as a customer need to deploy separately from KEDA. The agent would flow information from my KEDA functions to Azure to feed the Azure Portal with data, it should not be handled by the KEDA core.
Conclusion
I’ve been working on autoscaling on Kubernetes with customers and the on-ramping for it is not super easy, certainly if you want to scale on arbitrary metrics.
This makes Kubernetes-based event-driven autoscaling (KEDA) a great addition to the autoscaling toolchain, certainly for Azure customers, as they handle everything for us and I can just define how it should scale.
The adoption of KEDA will heavily depend on the community that arises around it, the number of scalers that are being added and how much integration and improvements the Azure Functions team does on their end.
It is very good to have KEDA and will make scaling apps on Kubernetes a lot more accessible – I am very happy and I’m certain others will like it as well.
KEDA and the Azure Kubernetes Adapter each have their own place and I hope they will both keep on being maintained going forward.
We are planning for KEDA 1.0 so now is the time to ask for things! What scaler would you like to have? Is there anything you think KEDA should handle? Feel free to create an issue!
Thanks for reading,
Tom.
Subscribe to our RSS feed