Azure Data Factory is one of those services in Azure that is really great but that doesn’t get the attention that it deserves.
It is a hybrid data integration service in Azure that allows you to create, manage & operate data pipelines in Azure. Basically, it is a serverless orchestrator that allows you to create data pipelines to either move, transform, load data; a fully managed Extract, Transform, Load (ETL) & Extract, Load, Transform (ELT) service if you will.
I’ve been using Data Factory a lot in the past year and it makes it very easy to create & manage data flows in the cloud. It comes with a wonderful monitoring experience which could be an example for other services like Azure Functions & Azure Event Grid where this would be beneficial.
However, Azure Data Factory was not perfect.
The drawbacks of Azure Data Factory
There were a couple of drawbacks & missing features when using the service:
- Only Supports Data Slicing – The only way to schedule your data pipeline was to run every x minutes, hours or days and process the data that was in that time slice. You couldn’t trigger it on demand or whatsoever.
- No Granular Scheduling Control – No granular control on when the pipeline should be triggered in terms of calendar scheduling ie. only run the pipeline during the weekend.
- Limited Operational Experience – Besides the Monitor-portal, the monitoring experience was very limited. It only supported sending email notifications that were triggered under certain criteria while it did not provide built-in metrics nor integration with Azure Monitor.
- JSON All The Things – The authoring experience was limited to writing everything in JSON. However, there was also support for Visual Studio, but even there it was only to edit JSON files.
- Learning Curve – The learning curve for new people was pretty steep. This is primarily because it was using mainly JSON and I think having a code-free experience here would make things a lot easier.
Last but not least, the most frightening factor was radio silence. And for a good reason…
Enter Azure Data Factory 2.0.
Azure Data Factory 2.0
During Ignite, Microsoft announced Azure Data Factory 2.0 that is now in public preview.
Azure Data Factory 2.0 takes data integration to the next level and comes with a variety of triggers, integration with SSIS on-prem and in Azure, integration with Azure Monitor, control flow branching and much more!
Let’s have a look at a couple of new features.
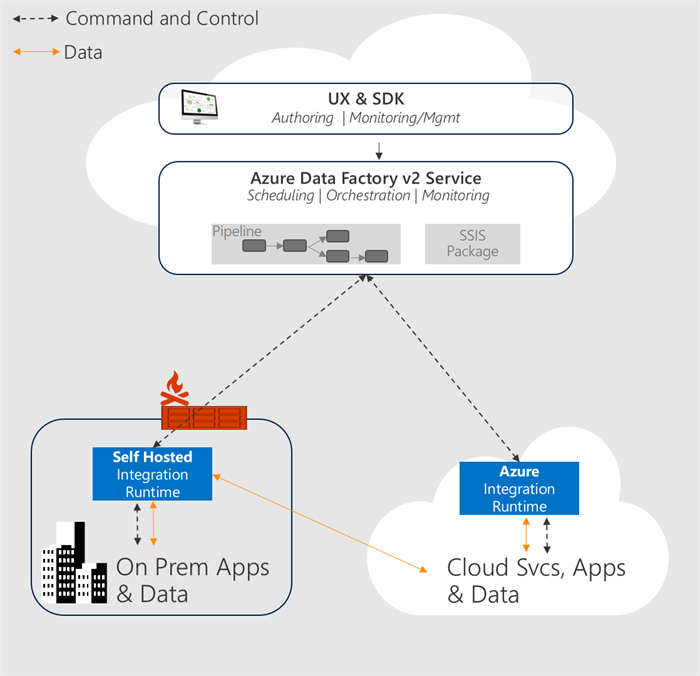
Introduction of Integration Runtime
A new addition is the concept of an Integration Runtime (IR). It represents a compute infrastructure component that will be used by an Azure Data Factory pipeline will use to offer integration capabilities as close as possible to the data you need to integrate with.
Every integration runtime provides you the capability to move data, execute SSIS packages and dispatch & monitor activities and come in three different types – Hosted in Azure, Self-Hosted (either in the cloud or on-premises) or Azure-SSIS.
Here is an overview of how you can mix and match them.
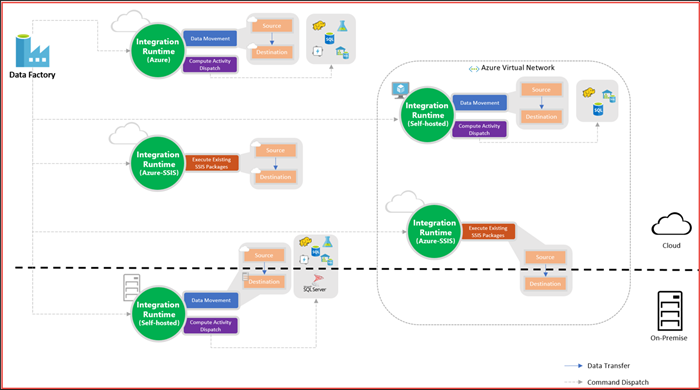
Basically, the Azure Data Factory instance itself is only in charge of storing the metadata that describes how your data pipelines will look like while at execution time it will orchestrate the processing to the Integration Runtime in specific regions to handle the effective execution.
This allows you to more easily work across regions while the execution is as close as possible.
As far as I can see, the self-hosted Integration Runtime also enables you to integrate with data that is behind a firewall without having to install an agent like you had to do in the past since everything is happening over HTTP.
Another big advantage here is that you can now run SSIS packages as part of your integration pipelines allowing you to re-use existing business intelligence that was already there, but now with the power of the cloud.
You can read more about the various Integration Runtimes in this article.
New pipeline triggers
Triggers, triggers, triggers! I think this is what excited me the most because because Data Factory only supported building data pipelines for scenarios where data slicing was used.
If you had scenarios where this was not the case, then there was no (decent) Data Factory pipeline that could help you.
The first interesting trigger: On-demand execution via a manual trigger. This can be done via .NET, PowerShell, REST or Python and it can be useful when you want to trigger a data pipeline at the end of a certain process, regardless of what the time is.
A second trigger is the scheduler trigger that allows you to define a very granular schedule for when the pipeline should be triggered. This can range from every hour to every workday at 9 AM. This allows you to still have the simple data-slicing model if you prefer that, or define more advanced scheduling if that fits your needs.
For example, we had to run pipelines only during the workweek. With v1, this is not possible and we have pipeline failures every Saturday & Sunday. With Scheduler Triggers we can change this approach and define that it should only be triggered during the week.
Another great addition is that you can now pass parameters to use in your pipeline. This can be whatever information you need, just pass it when you trigger it.
In the future, you will also be able to trigger a pipeline when a new file has arrived. However, by using the manual trigger, you could already set this up with an Azure Event Grid & Logic App as far as I see.
Last but not least – One pipeline can now also have multiple triggers. So, in theory, you could have a scheduler trigger but also trigger it manually via a REST endpoint.
It’s certainly good stuff and you can find a full overview of all supported triggers here.
Data Movement, Data Transformation & Control Flow Activities
In 2.0 the concept of Activities has been seperated into three new concepts: Data Movement, Data Transformation Activities & Control Flow Activities.
Control Flow Activities allows you to create more reactive pipelines in that sense that you can now react on the outcome of the previous activity. This allows you to execute an activity, but only if the previous one had a specific state. This can be success, error or skipped.
This is a great addition because it allows you to compensate or rollback certain steps when the previous one failed or notify people in case it’s required.
Control Flow Activities also provide you with more advanced flow controls such as For Each, Wait, If/Else, Execute other pipelines and more!
Here’s a visual summary:
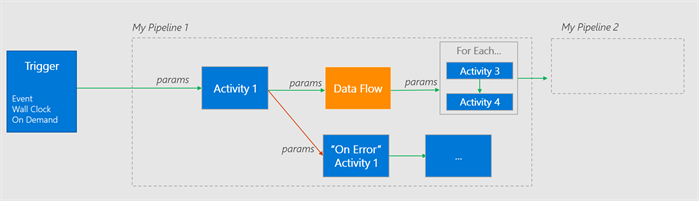
This tutorial gives you a nice run-through of the new control flow activities.
Authoring Experience
In the past, one of the biggest pains was authoring pipelines. Everything was in JSON and there was no real alternative besides the rest API.
In v2 however, you can use the tool that gets your job done by choosing from a variety of technologies going from .NET & Python, to pure REST or script it with PowerShell!
You can also use ARM templates that have embedded JSON files to automatically deploy your data factory.
But what I like the most is the sneak peek of the visual tooling that Mike Flasko gave at Ignite 2017:
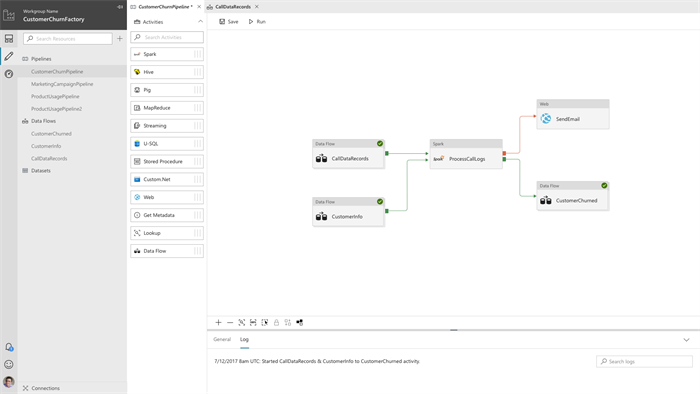
It enables you to author pipelines by simply dragging & dropping activities in the way your business process is modeled. This abstracts away the JSON structure behind it, allowing people to jump more easily on the Data Factory band wagon.
By having this visual experience it also gives you a clear overview of how all the services tie together and are also a form of documentation to a certain degree. If a new person joins the team he can easily see the big picture.
However, this is not available yet and is only coming later next year.
Mapping data with Data Flow
One feature that is not there yet, but is coming early 2018, is the Data Flow activity that allows you to define data mappings to transform your datasets in your pipeline.
This feature is already in v1 but the great thing is that for this one you will also be able to use the code-free authoring experience where it will help you create those mappings and visualize what they will look like.
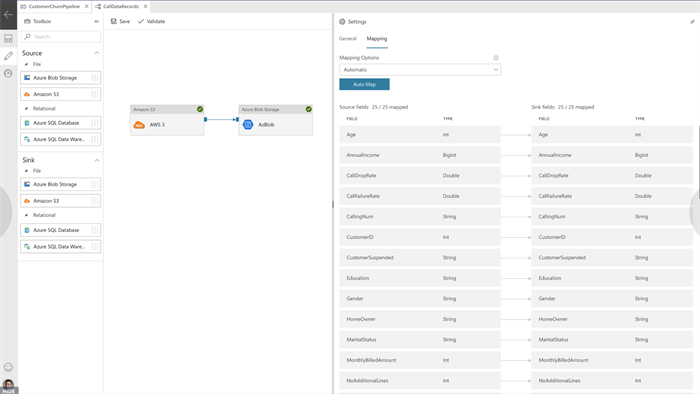
We currently use this in v1 and I have to say that it is very nice, but not easy to get there if you need to do this in JSON. This visualizer will certainly help here!
Improved Monitoring experience
As of October, the visual monitoring experience was added to the public preview which is very similar to the v1 tooling.
For starters, it lists all your pipelines and all their run history allowing you to get an overview of the health of your pipelines:
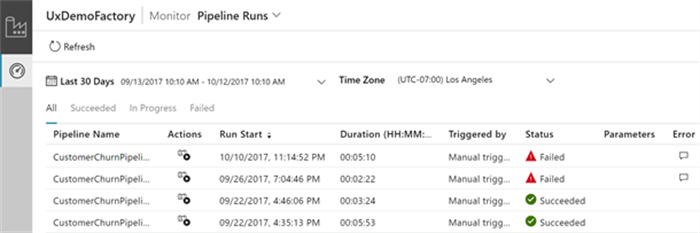
If you’re interested in one particular run, you can drill deeper and see the status of each activity. Next to that, if one has failed you can get more information on what went wrong:
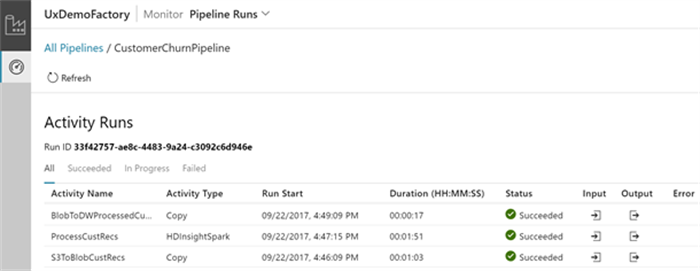
Next to that, you can also filter on certain attributes so that you can see only the pipelines that you’re interested in.
Another great aspect is that Azure Data Factory v2 now integrates with Azure Monitor and now comes with built-in metrics such as run, activity and trigger outcomes. This allows you to configure Azure Alerts based on those and can integrate with your overall alert handling instead of only supporting email notifications. This is a very big plus for me personally!
Diagnostic logs can now also be stored in Azure Storage, send to Azure Event Hubs & analyzed in Operations Management Suite (OMS) Log Analytics!
Read more about the integration with Azure Monitor & OMS here.
Taking security to the next level
One of the most important things in software is security. In the past, every linked service had its passwords linked to it and Azure Data Factory handled this for you.
In v2, however, this approach has changed.
For starters – When you provision a new Azure Data Factory, it will automatically register a new managed Azure AD Application in the default Azure AD subscription.
This enables you not only to copy data from/to Azure Data Lake Store, it also enables you to integrate with Azure Key Vault.
By creating an Azure Key Vault linked service, you can store the credentials of all your other linked services in a vault. This gives you full control of managing the authentication keys for the external services and giving you the capability to have automatic key rolling without breaking your data factories.
Authentication with Azure Key Vault is fully managed by Data Factory based on the Azure AD Application that was created for you. The only thing you need to do is grant your AD Application access on the vault and create a linked service in your pipeline.
More information about handling credentials in Data Factory can be found in this article or read more about data movement security here.
Migration Path to v2
As of today you can already start creating new pipelines for Azure Data Factory v2 or migrate your v1 pipelines over to v2. However, this is currently a manual process and not all features from v1 are currently available such as the Data Flow.
In 2018 they will provide a tool that can migrate your v1 pipelines to v2 for you so if it’s not urgent I’d suggest to sit back and wait for it to land.
Making Data Factory more robust over time
While I’m a fan of the recent changes to Azure Data Factory, I think it can be improved by adding the following features to make the total experience more robust:
- The concept of pipeline versioning where all my pipeline definitions, regardless of how they are created, have a version stamped on it that is being displayed in the Azure/Monitor portal. That way, we can easily see if issues are related to a new version that was deployed or if something else is going on.
- As far as I know, correlation ids are not supported yet in Azure Data Factory and would be a great addition to improve the overall operational experience even more. It would allow you to provide end-to-end monitoring which can be interesting if you’re chaining multiple pipelines, or integrate with other processes outside Data Factory. In the monitoring portal, you can currently see the parameters but would be nice if you could filter on a specific correlation id and see all the related pipelines & activities for that.
- While they are still working on the code-free authoring portal, I think they should provide the same experience in Visual Studio. It would allow us to have best of both words – A visualizer to author a pipeline, jump to the code behind for more advanced things and integrate it with source control without having to leave Visual Studio.
- Integration with Azure Data Catalog would be really great because then we can explore our internal data catalog to see if we have any valuable data sources and connect to them without having to leave the authoring experience.
But we have to be reasonable here – Azure Data Factory v2 was only recently launched into public preview so these might be on their radar already and only come later.
Conclusion
The industry is moving away from using one-data-store-to-rule-them-all and is shifting to a Polyglot Persistence approach where we store the data in the data store that is best suited. With this shift comes a need to build integration pipelines that can automate the integration of all these data stores and orchestrate all of this.
Azure Data Factory was a very good start, but as I mentioned it was lacking on a couple of fronts.
With Azure Data Factory 2.0 it feels like it has matured into an enterprise-ready service that allows us to achieve this enterprise-grade data integration between all our data stores, processing, and visualization thanks to the integration of SSIS, more advanced triggers, more advanced control flow and the introduction of Integration Runtimes.
Data integration is more important than ever and Azure Data Factory 2.0 is here to help you. It was definitely worth the radio silence and I am looking forward to migrating our current data pipelines to Azure Data Factory 2.0 which allows us to simplify things.
Want to learn more about it? I recommend watching the “New capabilities for data integration in the cloud” session from Ignite.
Thanks for reading,
Tom Kerkhove.
Subscribe to our RSS feed