Invictus Methodology
Codit has been creating integration architectures for years. These years of experience have resulted in a mature integration architecture and methodology, which we have named Invictus.
Like in the not-so-old days of BizTalk, it is vital to setup your messaging integrations in a way that promote reuse, agility and flexibility. Decoupling is an important concept to achieve this and underlying is the most important concept of decoupling. Decoupling manifests itself in several areas:
- On message format: When mapping data from source to target, we never do this directly but always with a common/canonical format in between.
- On consumption: The source system of the data has no knowledge of the potentially multiple consumers of that data. Likewise, the consumers of data have no knowledge of each other and make no assumptions on the source of the data.
- On availability: We cannot assume that all systems involved have the same availability.
- On message exchange patterns: the technical manner of receiving data (by push or pull) should be strict independent of the way of publishing the data.
- On status of data: Although the source system dictates the state of the data, it is only allowed to do so within its own domain, not throughout the entire landscape. For new consumers the data is new, but the data itself may be old.
Codit has taken these principles and concepts towards the cloud in the Invictus for Azure offering. Invictus for Azure is the Codit off-the-shelf integration solution that allows you to easily implement your integrations in Azure. Without going into much technical details, the picture below shows the various Azure components that are used in Invictus for Azure. It clearly shows that there is a strict decoupling between receive and send processing.
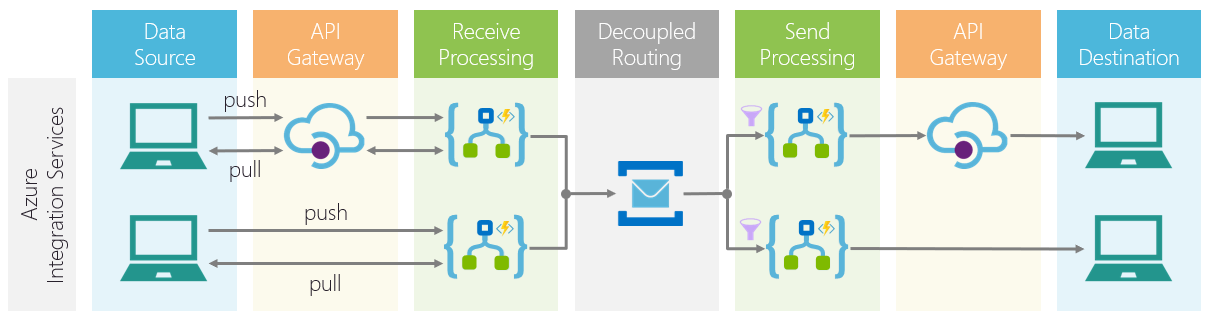
With Invictus for Azure and the architecture it supports, setting up quality integrations in Azure is a breeze.
Azure Data Factory
Integration in Azure is not only messaging but can also consist of large datasets. Although Logic Apps can handle large sets of data, there is a hard limit on that (see https://docs.microsoft.com/en-us/azure/logic-apps/logic-apps-limits-and-config for details). Besides that, the nature of Logic Apps is messaging. In other words, Logic Apps may not be the best tool to get the job done. For larger datasets, we can make use of Azure Data Factory. Azure Data Factory is Microsoft’s answer for moving and transforming large datasets.
The most noticeable parts of Azure Data Factory are pipelines and dataflows. Pipelines are similar to Logic Apps as they describe the workflow that needs to be done. A typical pipeline contains various sequential steps like copying data, invoking functions and triggering dataflows.
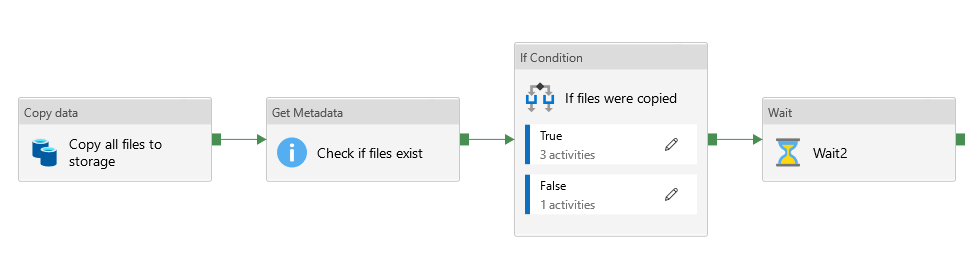
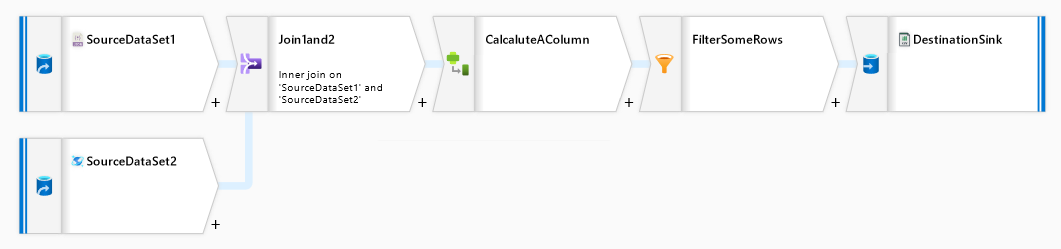
Dataflows can be compared to mapping one message to another, but it can do more, such as:
- joining different sets of data (streams)
- aggregation of streams
- filtering data from streams
Best of both worlds
Just like any tool by Microsoft, Azure Data Factory is flexible and powerful. But the saying with great power comes great responsibility has never been more true. Microsoft by itself will not prevent you from creating tightly coupled integrations using Logic Apps, and the same applies to Azure Data Factory. By not taking decoupling into account, we end up with tightly coupled pipelines and dataflows, losing the flexibility and agility the business requires from IT.
So why not combine both? Can we setup Azure Data Factory with ideas and principles from the Invictus Methodology? In regards to messaging, can we bridge Azure Data Factory and messaging so that we detect and publish changes from large datasets?
Invictifying Azure Data Factory
The cornerstone of Invictifying Azure Data Factory is decoupling. We achieve this by splitting up pipelines and dataflows, similar to Logic Apps. With the Invictus Methodology in mind, the architecture for Azure Data Factory will look like this:
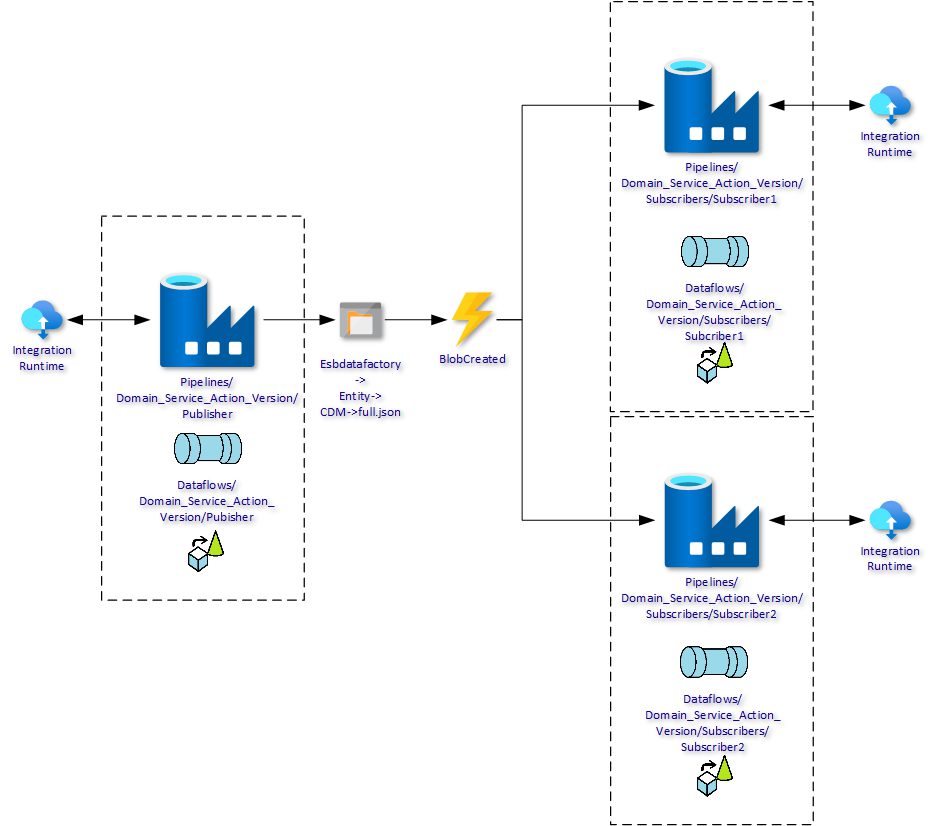
The picture shows that there is a clear separation between the source system and the target systems, just like the Logic App setup using the architecture described by Invictus. Instead of using an Azure Service Bus, we make use of Azure Blob Storage. Any subscribing pipeline acts on the BlobCreatedEvent.
All consuming pipelines act on the same entire dataset in storage. That is fine but what if we only want to get the changes in the dataset. For one of our clients, it was decided to not send all the data every time, but to switch to changes-only (deltas), so the client only received data when there was changes. For this we can use the Changefeed (see https://docs.microsoft.com/en-us/azure/cosmos-db/change-feed-design-patterns for details) mechanism that is in Azure Cosmos DB.
In the picture below a pipeline is shown that is subscribed to the same BlobCreatedEvent but does the interaction with Azure Cosmos DB to determine the changes.
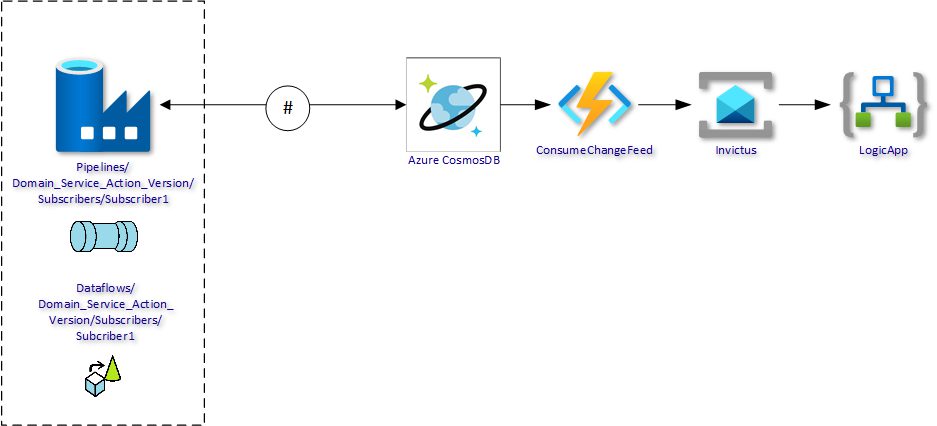
The mechanism to determine if a record has changed or not is fingerprinting. We are not comparing each and every field, but we generate a fingerprint for each record and compare it with the fingerprint based on the data in Azure Cosmos DB. A matching fingerprint means the data is exactly the same so it should be filtered from the incoming stream. All data with a different fingerprint is saved/updated in Azure Cosmos DB. The data in Azure Cosmos DB is in the canonical format.
The update or insert in Azure Cosmos DB will trigger the Changefeed. The Changefeed is captured by an Azure Durable Function which splits the Changefeed documents in separate messages and publishes each message in the Invictus Service Bus. From there, the message can be picked up by any Logic App for further processing.
For subscribers that require all data at a regular interval, we do not couple them with the incoming data stream. Instead, we use Azure Cosmos DB as data source by creating an Azure Data Factory pipeline that is scheduled to retrieve all data from Azure Cosmos DB. After transforming the data stream to the required format, the data is sent to the target system.
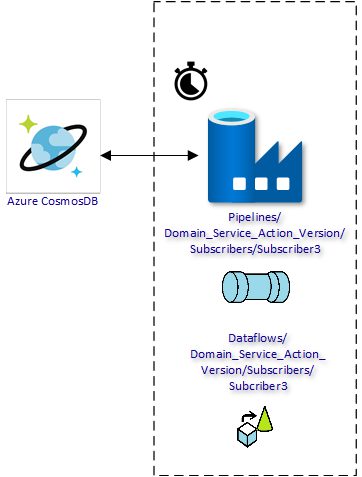
This way any subscriber can retrieve all data any time. This is totally separated from the frequency of the source system publishing the data.
Summary
Maximizing decoupling of systems is an important goal when setting up integrations. This not only applies to Logic Apps but other Microsoft integration technologies as well. In this blog, I’ve tried to show you that Azure Data Factory becomes even greater if we apply the same principles and ideas we use in messaging.
Subscribe to our RSS feed