Scenario
Let’s get our hands dirty and try to develop the following old-school integration scenario: receive a flat file from disk, archive it, convert it to XML, transform the result and finally write the XML message again to disk.

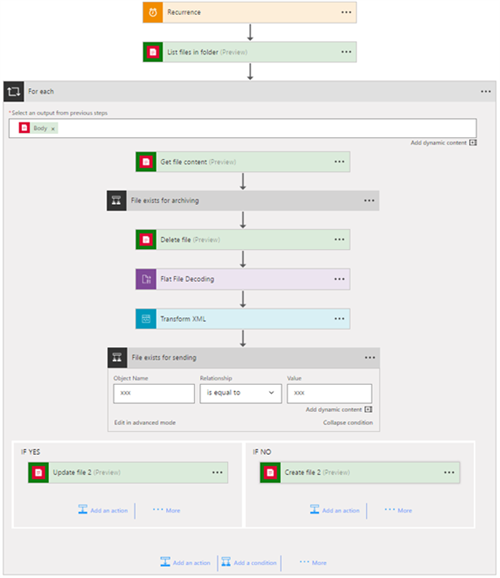
Based on some documentation on the internet, I got the following scenario working in minutes! The Logic App kicks off with a Reccurrence trigger. It loops over all files in the input folder, reads their content and deletes them. The flat file content gets archived. Next, we decode it and perform a transformation towards the desired format. The result gets written to the file system again, where we check if we need to perform a Create file or an Update file action.
Issues
When this Logic Apps gets analysed by people with a background of enterprise integration, you’ll get the following remarks:
We cannot reuse this development effort in similar integrations!
As an example: sending a file will typically be a combination of multiple Logic App actions working together: inject values into the file name and decide whether an update or create should happen. It’s not desired to redevelop this functionality repeatedly for every Logic App that requires it! This will cost us too much time and we will end-up with different flavours of this functionality, which is not maintainable.
This workflow is too tightly coupled with its receiving transport protocol!
If we want to change the receiving transport protocol from FILE to FTP, we almost need to redevelop the Logic App from scratch again, as the subsequent actions have a hard dependency on it. We are even not sure if the FTP connector has the same actions available as the FILE connector. We have also integrations that are using SFTP in production, but are tested with FTP in the other environments. With this design, we cannot switch easily between environments.
There is no option to resume this workflow if it fails during processing!
For our solution, the resubmit functionality of Logic Apps is useless. The Logic App is initiated by a simple Reccurrence trigger. If we initiate a resubmit, it behaves exactly the same as if a new trigger is fired. If something goes wrong inside the Logic App, it will take a huge (manual) effort to get that message reprocessed again. In case of enterprise integration, we’re processing thousands of files, so it will be a cumbersome experience for our operations personnel.
This is spaghetti interfacing. There’s no loose coupling or pub/sub involved!
This is real point-to-point interfacing! If we design our new integration platform in this way, we will end up with unmanageable spaghetti interfacing. Production proven integration patterns like loosely coupling and publish / subscribe are nowhere to be found. A redeployment is required in case another backend system is interested in this dataset.
This workflow handles multiple files, which results in difficult troubleshooting!
This specific Logic App loops over every single file in the input folder. Logic Apps for each statements are – by default – executed in parallel, so an issue with one file will not block the processing of the other files. In case there is a problem with one file, the Logic App will end up in a Failed state. To resolve the issue, an operator will need to scroll through each iteration until the faulted message is found. Again, a manual intervention will be required to resume this file.
Conclusion
Do I agree with the statements above? Of course I do, I wrote them myself! However, this is exercise should not result in concluding that Logic Apps can’t handle the job! Contrary, this is intended to create awareness about potential pitfalls when doing enterprise integration within Logic Apps. Understanding these pitfalls is a first step in designing Logic Apps solutions for robust enterprise integration!
Want to learn more? Check out my Integration Monday session on this matter!
Hope to see you there!
Toon
Subscribe to our RSS feed