A while ago I wrote about the launch of Kubernetes Event-Driven Autoscaling (KEDA) which is a Microsoft & Red Hat partnership that would make autoscaling Kubernetes workloads a lot easier – If you have missed it, you can read it here!
![]()
Ever since KEDA was announced, it has been getting a lot of attention and people started contributing to it. I’ve been one of those people for the simple reason that this is a must-have in your application infrastructure.
Why? It’s simple – Kubernetes is hard if you’re new and that’s where KEDA truly shines by making autoscaling simpler.
Today is a big day for KEDA as we are announcing KEDA v1.0 – Read the official announcement here!
What is Kubernetes Event-Driven Autoscaling (KEDA)?
Without KEDA, it is up to you to define how your deployments have to scale by creating Horizontal Pod Autoscalers (HPA). But before you can do that, you need to run a metric adapter to pull the metrics from the source that you want.
If you need to get metrics from multiple sources by using multiple adapters, you are out of luck because only one is supported (unless that changed recently).
Here is an overview of the whole setup:
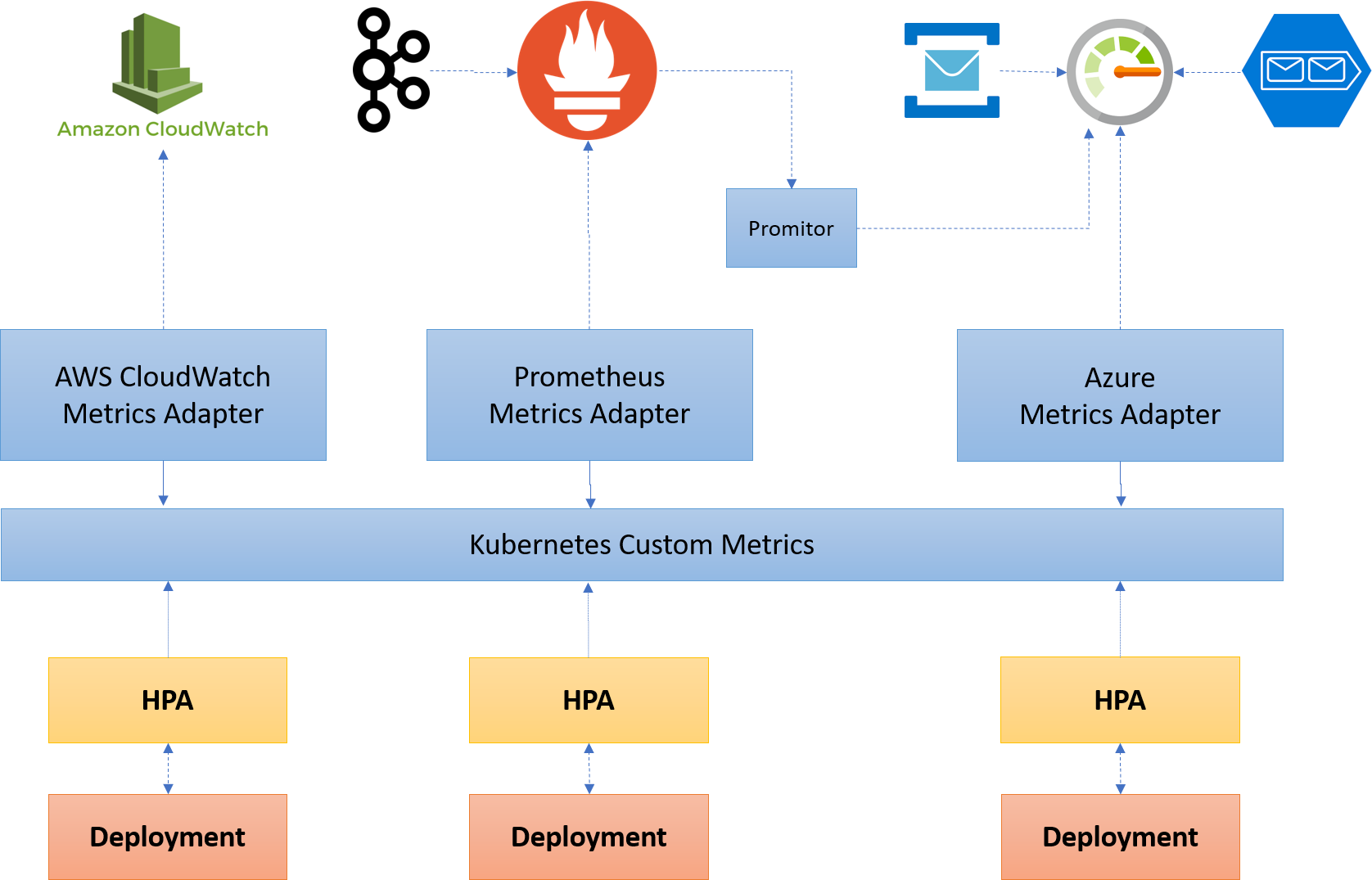
That is a lot of infrastructures to just scale your app with an HPA.
With Kubernetes Event-Driven Autoscaling (KEDA), however, it pulls from a variety of sources and automatically scales your deployments from 0 to n-instances based on your configuration in the ScaledObject.
The good thing is that KEDA didn’t build its own scaling mechanism but creates HPAs behind the scenes when it needs to add instances. If 0 instances are required, it will delete the HPA.
The landscape becomes a bit simpler, only asking you to run the KEDA runtime:
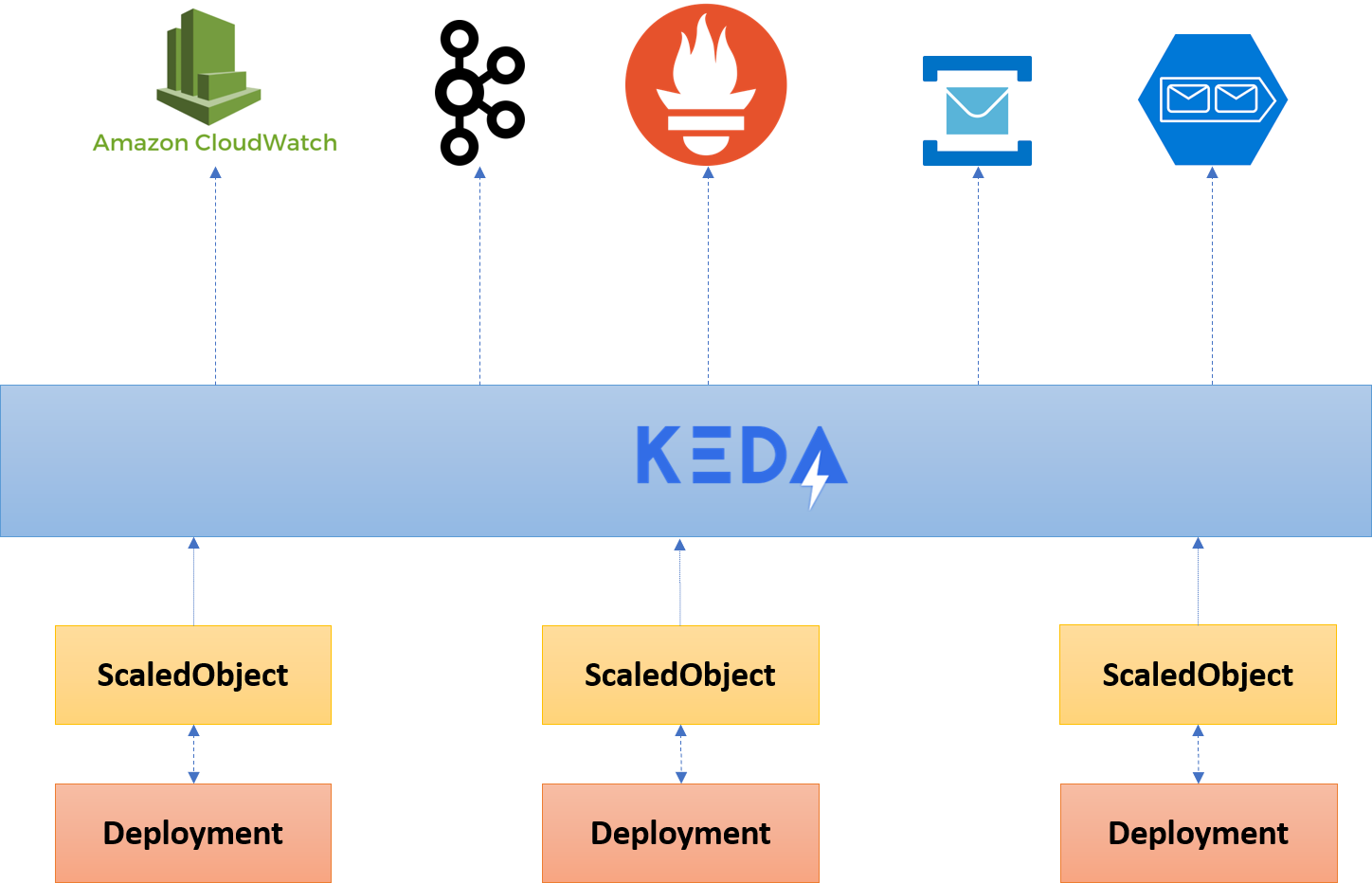
Again, I wrote about this before so if you want to have a better understanding you can read it here.
What’s New?
Scaling Jobs with ScaledObject
Before v1.0 the only workloads that you could scale were Kubernetes Deployments which are pods that are running infinitely.
We’ve introduced support for scaling Kubernetes Jobs which get spun up and run to completion!
Rather than processing multiple events within a single deployment, a single Kubernetes Job is scheduled for each detected event. That job will initialize, pull a single event from the message source, and process to completion and terminate.
You can learn more about it in our documentation.
Production-grade Authentication with TriggerAuthentication CRD
ScaledObject uses scale triggers to determine if deployment needs to be scaled in or out. Some of these, however, require to authenticate first which had to be configured on the deployment as secret/environment variable and referred to in the ScaledObject.
This is not ideal because:
- Difficult to efficiently share auth config across
ScaledObjects - No support for referencing a secret directly, only secrets that are referenced by the container
- No support for other types of authentication flows such as pod identity where access to a source could be acquired with no secrets or connection strings
That’s why we are happy to introduce the TriggerAuthentication CRD which allows you to define how a trigger should authenticate, link it to your ScaledObject and you are good to go!
This allows you to not only work more efficiently as a team, but also to re-use trigger authentication by using them with other ScaledObjects.
TriggerAuthentication allows you to use pod identity allowing you to remove secrets from your workloads!
As of today, we support using Azure Managed Identity which is based on the Azure AD Pod Identity OSS project but we are planning to add more providers such as AWS.
You can learn more about it in our documentation.
Simplifying Deployments
We’ve made it a lot simpler to get started with KEDA – One aspect of it is making it easier to deploy KEDA!
You can now integrate KEDA in your deployment pipeline:
- Support for Helm 2.x & 3.0 and is published on hub.helm.sh
- Support for Operator SDK has been added
The next step is to publish KEDA on Operator Hub to make it, even more, simpler – Stay tuned (#469)!
You can learn more about it in our documentation.
Scalers, Scalers, Scalers!
The power of KEDA lies in the scalers it supported – I’m happy to announce that KEDA ships with 13 scalers out-of-the-box such as Apache Kafka, Azure Service Bus, Prometheus, NATS Streaming, GCP Pub/Sub, Rabbit MQ and more.
Don’t see the scaler you need? With our new external scaler you can integrate with other systems to autoscale on them! Here’s a nice example from the community.
Is your company building a product on which we can autoscale? We are more than happy to accept contributions! We even have a guide to help you.
Making It Easier To Get Started
I think products are only as good as the documentation is – That’s why we’ve introduced keda.sh!
Our goal is to make it easier for new people to get started and learn what KEDA is, what the architecture is and how they can get involved.
Next to that, you can get the latest overview of the scalers that are supported out-of-the-box and who is maintaining them.
Are you more of a code guy? No worries – We now have a dedicated samples GitHub repo with samples for a variety of languages and scalers!
Run Azure Functions Anywhere
With this release, you can now safely run your Azure Function apps on Kubernetes and is endorsed by the product group!
This allows you to build your serverless apps once and re-use them on other infrastructure if you wish to do so.
☝ Do note that you cannot create Azure Support tickets for your workloads so think twice.
What’s Coming?
This release is just the beginning! While there have not been any official commitments yet, here are a few key areas we are working on as well as what I’d like to focus on.
KEDA has started as a partnership between Microsoft & Red Hat, but we aim to make it a fully open product that everybody can use. Because of that, we are working on donating KEDA to Cloud Native Computing Foundation (CNCF) as a new sandbox project!
The true power of KEDA is the event sources that are available to scale on – We will focus on making it easier to contribute new scalers, look for new scaler maintainers and plan for new ones based on customer needs.
Last but not least, running KEDA should be easy – My goal is to simplify this and give you access to all the information & controls that you need to easily operate KEDA. With our early KEDA dashboard prototype this already becomes easier but we’d like to improve it by becoming a first-class citizen in the KEDA suite, but we need help! Next to that, wouldn’t it be nice if you could query for more information by using a CLI?!
Conclusion
Kubernetes Event-Driven Autoscaling (KEDA) v1.0 is a very big step forward and makes application autoscaling a lot simpler!
I’m very sure that this will help our customers focus on building their Kubernetes applications rather than figuring out how to scale their deployments and what infrastructure they need to get all the required info.
Does that mean KEDA is perfect? Certainly not! There is still a lot of work to do in terms of governance, new scalers, operating it and making it easier to use.
Donating KEDA to Cloud Native Computing Foundation (CNCF) as a new sandbox project is the next logical step to build a more open community so that other vendors jump in and help build a scaler-ecosystem.
The future looks promising – What are you most interested in?!
Thanks for reading,
Tom.
Subscribe to our RSS feed