What is Azure Synapse
Azure Synapse is a data analytics service that allows you, amongst other things, to query data that resides in various data sources via plain SQL statements.
For instance, you can query data that is stored in an Azure Data Lake Gen2 via Azure Synapse using SQL statements, and that’s what we’ll do in this article.
To learn more about Azure Synapse, check out this page.
Architecture Overview
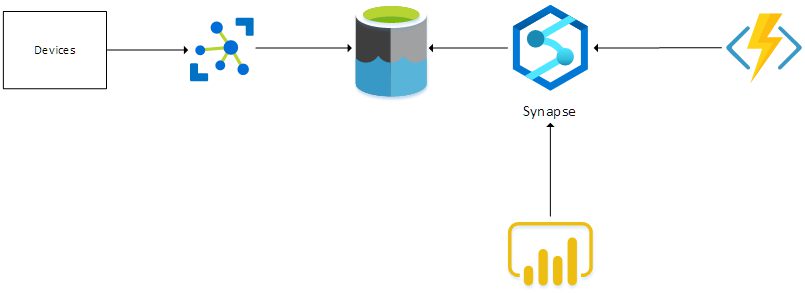
When collecting telemetry from multiple devices, we need an IoT gateway that accepts all telemetry. In this case, we’ll be using an Azure IoT Hub. The raw telemetry that is received from the devices is dumped in a Data Lake. Azure Synapse is linked to the Data Lake and this makes sure that SQL-like queries can be executed on the data that resides in the Data Lake.
An Azure Function uses this functionality to query the received raw telemetry and transform the data into a curated dataset. A report can be built in PowerBI, which uses the Synapse connector to query the curated dataset and display the results.
Storing Raw Telemetry in the Data Lake
Storing the telemetry that is received in IoT Hub to a Data Lake is actually super simple. This can be done by leveraging the IoT Hub Routing functionality.

Building Parquet Files
An Azure Function triggered by a timer queries the view that we have defined in Synapse, to retrieve the telemetry data that has been received since the function’s last run.
The function will build a parquet dataset, storing that dataset in another container in the Data Lake. I’ve chosen a timer-triggered Function instead of a Blob-trigger, because I want to combine data from multiple input files in one parquet file. Be aware that the Azure Function needs to have the Storage Blob Data Contributor role assigned to be able to read and write blobs in the Data Lake.
Reporting Via PowerBI
Use PowerBI Desktop to create some simple reports on the curated Parquet dataset.
To achieve this, you must create a DirectQuery dataset to a SQL Server datasource. The dataset points to the Serverless SQL endpoint of Azure Synapse. This will allow PowerBI to issue SQL statements against the Serverless SQL pool in Synapse.
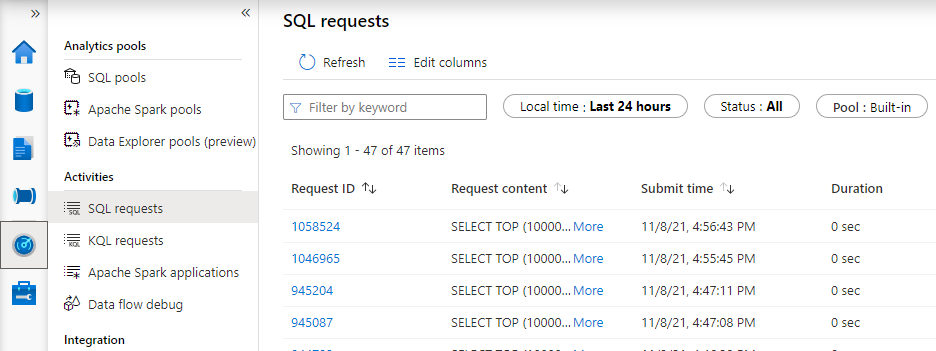
The SQL statements that are generated by your PowerBI reports can be viewed via the ‘Monitor’ blade in your Azure Synapse Workspace studio:
Wrapping Up
This article shows how easy it can be to query data that is stored in a Data Lake using SQL commands via Azure Synapse, and how you can make use of hierarchies to partition the data and improve query performance.
While this is certainly not a replacement for services such as Azure Data Explorer, Azure Timeseries Insights and InfluxDb, in terms of performance and features, it allows you to build reports to get insights into your data.
Thanks for reading,
Frederik
Subscribe to our RSS feed