Scenario
Let’s discuss the scenario briefly. We need to consume data from the following table. All orders with the status New must be processed!
The table can be created with the following SQL statement:
First Attempt
Solution
To receive the data, I prefer to create a stored procedure. This avoids maintaining potentially complex SQL queries within your Logic App. The following stored procedure selects the first order with status New and updates its status to Processed in the same statement. Remark that it also returns the @@ROWCOUNT, as this will come in handy in the next steps.
The Logic App fires with a Recurrence trigger. The stored procedure gets executed and via the ReturnCode we can easily determine whether it returned an order or not. In case an order is retrieved, its further processing can be performed, which will not be covered in this post.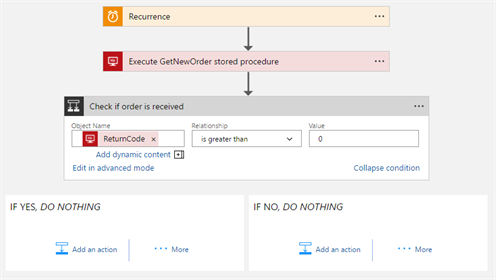
Evaluation
If you have a BizTalk background, this is a similar approach on using a polling SQL receive location. One very important difference: the BizTalk receive adapter executes the stored procedure within the same distributed transaction as it persists the data in the MessageBox, whereas Logic Apps is completely built on API’s that have no notion of MSDTC at all.
In failure situations, when a database shuts down or the network connection drops, it could be that the order is already marked as Processed, but it never reaches the Logic App. Depending on the returned error code, your Logic App will end up in a Failed state without clear description or the Logic App will retry automatically (for error codes 429 and 5xx). In both situations you’re facing data loss, which is not acceptable for our scenario.
Second attempt
Solution
We need to come up with a reliable way of receiving the data. Therefore, I suggest to implement a similar pattern as the Azure Service Bus Peek-Lock. Data is received in 2 phases:
- You mark the data as Peeked, which means it has been assigned to a receiving process
- You mark the data as Completed, which means it has been received by the receiving process
Next to these two explicit processing steps, there must be a background task which reprocesses messages that have the Peeked status for a too long duration. This makes our solution more resilient.
Let’s create the first stored procedure that marks the order as Peeked.
The second stored procedure accepts the OrderId and marks the order as Completed.
The third stored procedure should be executed by a background process, as it sets the status back to New for all orders that have the Peeked status for more than 1 hour.
Let’s consume now the two stored procedures from within our Logic App. First we Peek for a new order and when we received it, the order gets Completed. The OrderId is retrieved via this expression: @body(‘Execute_PeekNewOrder_stored_procedure’)?[‘ResultSets’][‘Table1’][0][‘Id’]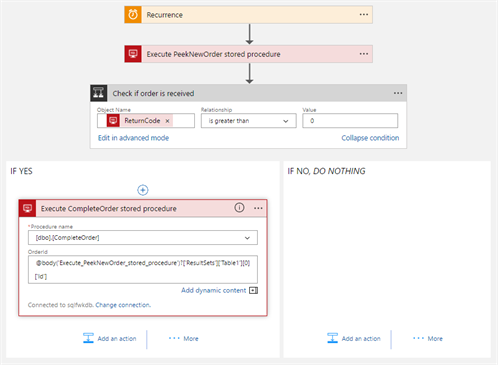
The background task could be executed by a SQL Agent Job (SQL Server only) or by another Logic App that is fired every hour.
Evaluation
Happy with the result? Not a 100%! What if something goes wrong during further downstream processing of the order? The only way to reprocess the message is by changing its status in the origin database, which can be a quite cumbersome experience for operators. Why can’t we just resume the Logic App in case of an issue?
Third Attempt
Solution
As explained over here, Logic Apps has an extremely powerful mechanism of resubmitting workflows. Because Logic Apps has – at the time of writing – no triggers for SQL Server, a resubmit of the Recurrence trigger is quite useless. Therefore I only want to complete my order when I’m sure that I’ll be able to resubmit it if something fails during its further processing. This can be achieved by splitting the Logic App in two separate workflows.
The first Logic App peeks for the order and parses the result into a JSON representation. This JSON is passed to the next Logic App.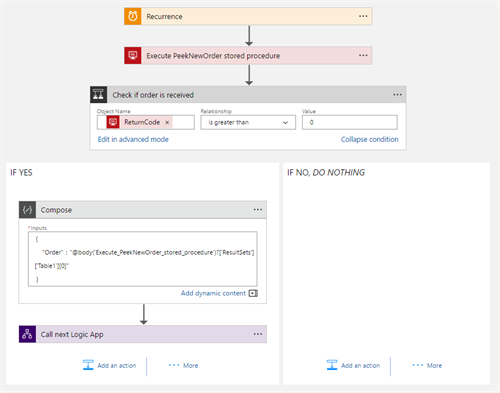
The second Logic App gets invoked by the first one. This Logic App completes the order first and performs afterwards the further processing. In case something goes wrong, a resubmit of the second Logic App can be initiated.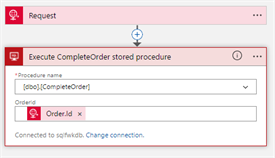
Evaluation
Very happy with the result as:
- The data is received from the SQL table in a reliable fashion
- The data can be resumed in case further processing fails
Conclusion
Don’t forget that every action is HTTP based, which can have an impact on reliability. Consider a two-phased approach for receiving data, in case you cannot afford message loss. The same principle can also by applied on receiving files: read the file content in one action and delete the file in another action. Always think upfront about resume / resubmit scenarios. Triggers are better suited for resubmit than actions, so if there are triggers available: always use them!
This may sound overkill to you, as these considerations will require some additional effort. My advice is to determine first if your business scenario must cover such edge case failure situations. If yes, this post can be a starting point for you final solution design.
Liked this post? Feel free to share with others!
Toon
Subscribe to our RSS feed