This blog post focuses on consuming existing Logic Apps from within other Logic Apps, also known as nested workflows. It’s a nice feature, but as usual: be aware of the caveats!
Scenario
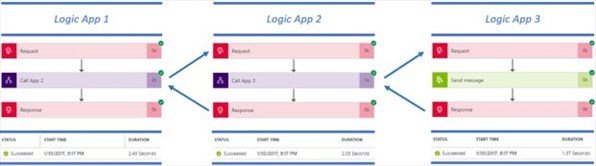
Let’s take the following scenario as a base to start from. Logic App 1 is exposed as a web service. It consumes Logic App 2 which calls on its turn Logic App 3. Logic App 2 and 3 are considered to be reusable building blocks of the solution design. As an example, Logic App 3 puts a request message on the particular queue. Below you can find the outcome of a successful run that finishes within an acceptable timeframe for a web service.
Exception Scenario
If you stick to the above design, you’ll discover unpleasant behavior in case you need to cope with failure. Building cloud-based solutions means dealing with failure in your design, even in this basic scenario. Let’s simulate an exception in Logic App 3, by trying to put a message on a non-existing queue. As a result, Logic App 1 fails after 6 minutes of processing!
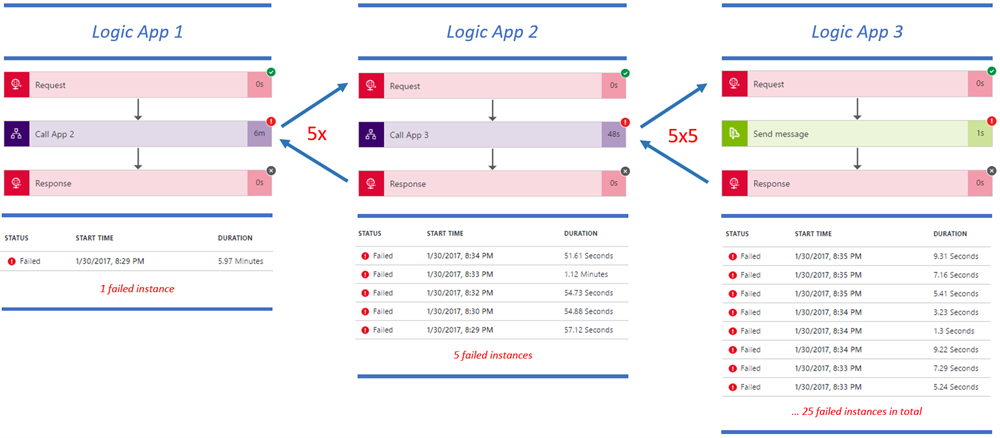
I expected a long delay and potentially a timeout, but those 6 minutes were a real surprise to me. The reason for this behavior is the default retry policies that are applied on Logic Apps. I consulted the documentation and that explains everything. Logic App 1 was fired once. Logic App 2 got retried 4 times, which results in 5 failed instances. The third workflow got even executed 25 (5×5) times.
The retry interval is specified in the ISO 8601 format. Its default value is 20 seconds, which is also the minimum value. The maximum value is 1 hour. The default retry count is 4, 4 is also the maximum retry count. If the retry policy definition is not specified, a fixed strategy is used with default retry count and interval values. To disable the retry policy, set its type to None.
Optimize the retry policies
Time to overwrite those default retry policies. For Logic App 1, I do not want any retry in case Logic App 2 fails. This is achieved by updating the code view:

In Logic App 2, I configure the retry policy to retry once after 20 seconds:

The result is acceptable from a timing perspective:
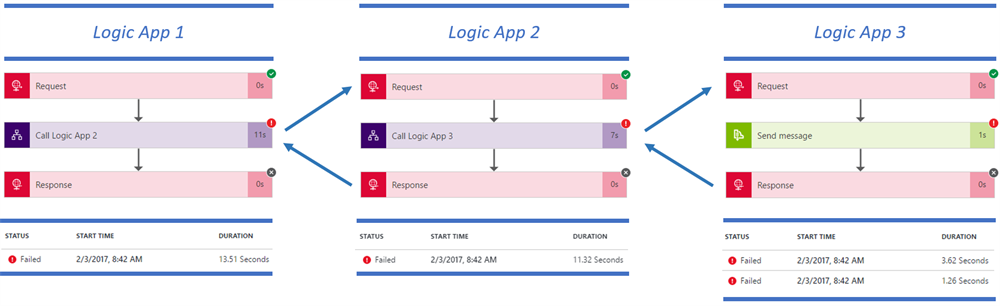
On the other hand, the exception message we receive is completely meaningless. Check out this post to learn more about exception handling in such a situation.
Implement fire and forget
In the previous examples, we invoked the underlying Logic App in a synchronous way: call the Logic App and only continue if the Logic App has completed its processing. For those with a BizTalk background: this is comparable with the Call Orchestration shape. As Logic Apps gives you complete freedom on where to put the Response action in your workflow, you can also go for a fire-and-forget pattern, comparable with the Start Orchestration shape. This can be achieved by placing the Response action right after the Request trigger. Via this way, these reusable Logic Apps execute independently from their calling process.
This eventual consistency can have an impact on the way user applications are built and it requires also good operational monitoring in case asynchronous processes fail. Remark in the example below, that the consuming application is not aware that Logic App 3 failed.
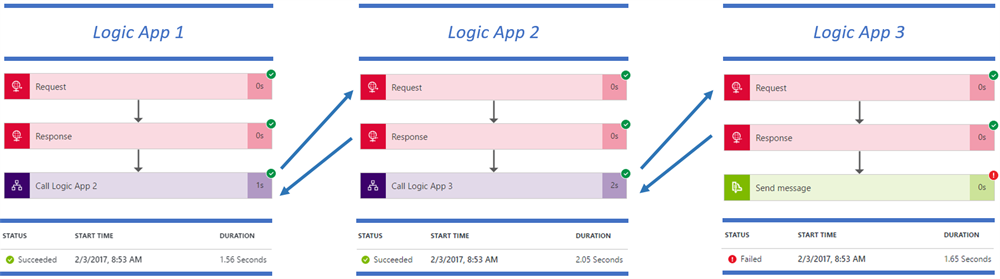
Update: Recently I discovered that it’s even possible to leave out the Response action within the nested workflows. Just ensure to update the consuming Logic App action with the following expression: “operationOptions”: “DisableAsyncPattern”. This is even more fire-and-forget style and will improve performance a little bit.
This solution reduces processing dependencies between the reusable Logic Apps. Unfortunately, the design is still not bullet-proof. Under a high load, throttling could occur in the underlying Logic Apps, which could result in time-outs when calling the nested workflows. A more convenient design, is to put a Service Bus queue in between. This increases on the other hand the complexity of development, maintenance and operations. It’s important to assess this potential issue of throttling within the context of your business case. Is it really worth the effort? It depends on so many factors…
Monitoring
As a final topic, I want to demonstrate the nested workflows all share a common identifier. The parent workflow has a specific ID of its instance.
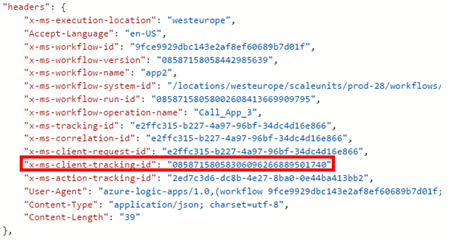
This ID appears in every involved Logic App run execution, in the form of a Correlation ID. This ID can be used to link / correlate the Logic App instances with each other.

This ID is handed over to the underlying workflow, via the x-ms-client-tracking-id HTTP Header.
Feedback to the product team
It’s fantastic that you get full control on the retry policies. The minimal retry interval of 20 seconds seems quite long to me, if you need to deal with sync web service scenario. I found also a nice suggestion to include an exponential back-off retry mechanism. Implementing circuit breakers would also be nice to have!
The monitoring experience for retried instances could be improved. In the Azure portal, they just show up as individual instances. There’s no easy way to find out that they are all related to each other. Would be a great feature if all runs with the same Correlation ID are grouped together in the default. Like it? Vote here!
Conclusion
Logic Apps nested workflows are very powerful to reuse functionality in a user-friendly way. Think about the location of the Response action within the underlying Logic App, as this greatly impacts the runtime dependencies. Implement fire and forget if your business scenario allows it and consider a queuing system in case you need a scalable solution that must handle a high load.
Thanks for reading!
Toon
Subscribe to our RSS feed