Intro
At Codit we always want to learn and train our colleagues in new technologies. And there is no better way to train than working on an actual (internal) project. Our latest project is the UEFA 2021 challenge. In previous blogposts we wrote about the general setup and about using AI to predict the outcome. In this post we zoom in on the models we use.
You cannot use AI without data. The dataset you use determines for a large part what your model will look like. For this project we focused on two approaches:
- Looking at the quality of the players of all the teams
- Looking at the results of previous matches
Each approach was taken up by a separate subteam. Each team describes their work below. They both used Azure Machine Learning (abbreviated as AzureML) to develop their models.
The Quality model
The quality approach to football result prediction began with the widely accepted cuisine idea that premium ingredients for any given recipe should lead to a superior outcome.
Randomness plays a big part in sports. Football is such a low scoring game, it is estimated that 40% of uncertainty influences the final result. It seems that the right tool for this job was certainly a time machine, but since Machine Learning is all we have at present time, the challenge was to use a prediction model that would attempt to take away the randomness out of the score.
The beauty of Azure Automated ML is that you do not need to know about Data Science, maths or even the topic and the data you are dealing with. It all starts with your own curiosity:
- What do my colleagues mean by terms such as ‘quality players’, ‘clinical finish’, ‘deserved to win’, ‘goal hunger’?
- How much does friendship between players enhance the performance of national squads?
- Is it true? The famous quote where history repeats itself and at the end Germany always wins?
- Can you predict thrilling matches so that I can skip the boring ones?
- How well does a player’s market value translate into sustained player performance?
- Is there a measure in football statistics more successful than others at predicting outcomes?
Since the goal of this fun project was to predict number of goals, the chosen machine learning experiment was based on regression algorithms, the fancy term to say that the output/label would be numbers.
The first task was to gather player stats of the season so far, including all the national leagues and international competitions. Since selection of players to form national squads is not public until a few days before the start of the competition, players and statistics from World Cup qualifiers and Nations league were used.
The second task was to build a dataset that would be used to experiment and answer the questions we had. Azure ML Studio came in very handy with integrated Jupyter notebooks, the selected approach to lookup, join and prepare data in a repeatable fashion, since different squads and matches would be coming up in the future.

Some of the metrics that have been used in the process:
- Normalised players rankings across competitions, adding more weight to international competitions such as 20-21 UEFA Champions league.
- Average of expected goals, a very popular stat that reflects the team’s ability to generate quality opportunities.
- Expected goals conceded, or the measure of defensive prowess.
- Difference of teams’ attack, midfield, and defensive rating.
There is no harm (to a certain extent) in using as many columns as you can find for your dataset. The importance of each data column will be provided in the explanation of every experiment you run.
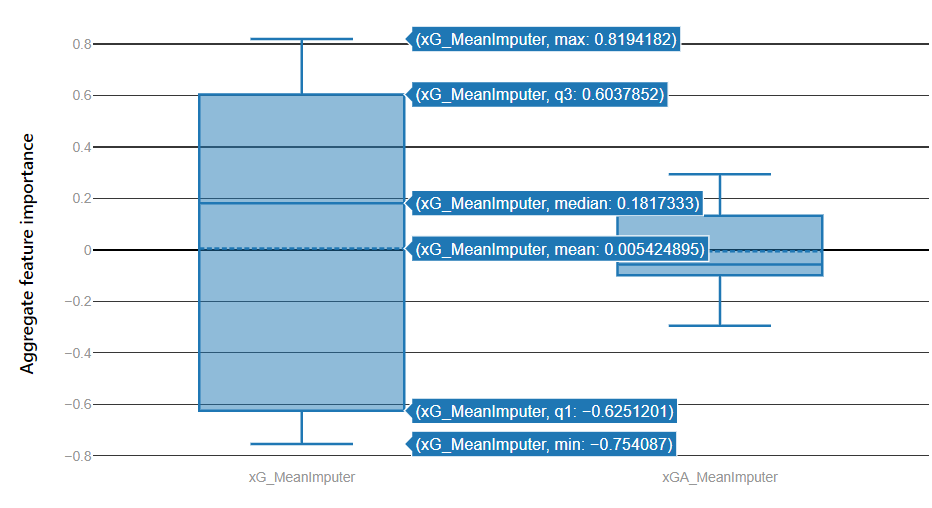
Bear in mind though, those same columns would have to be provided in your future predictions. An example would be including match shots on target in your dataset: for future predictions you might have to decide whether an average of those in the last 5 matches would be a sensible assumption.
The history model
The history approach purely took into account historical statistics, essentially asking the question: Given the recent performance of both teams, what will the result of the match be? To answer this question, we needed historical data about football matches.
At first a dataset of all international football results – ever – was gathered. With these data points the following model features could be calculated up until the date of a match: win rate, loss rate, goals scored and goals conceded of both teams.
Additionally, another dataset was used that contained every Fédération Internationale de Football Association (i.e. FIFA) world ranking for every team at any time. With this data the world rank of both teams at the time of the match could be determined. The FIFA world rankings were only created in 1992, so any match before that was filtered out.
After obtaining the datasets and the required metrics (i.e. data acquisition), the data had to be prepared (i.e. data engineering). This included the determination of the features (e.g. win rate) and targets (e.g. the result of a match) for the ML-model. The trickiest part of ML is often the data preparation. This is because not all gathered data might be necessary for the ML-model. The goal of the data preparation is to get the data points that are representative for the required prediction. A part of this is intuition. For example:
- I expect the results of friendly matches to not be representative of Euro Cup matches, since friendly matches are not as important to the teams.
Another part of this is simply trial-and-error. One can theorize about what should and should not be useful all day long, but at the end of the day you just have to just try and see if any changes do indeed have a positive impact on the prediction model. Don’t rely on assumptions alone.
Finally, different subsets of the datasets were created using Python, Jupyter Notebook and trial-and-error stored and processed within Azure ML. Using the Automated ML and regression statistics, all the subsets were trained and validated (providing an accuracy score) over a bunch of ML-algorithms (see below). The goal was to prompt for an accuracy higher than random guessing (i.e. above 33%).
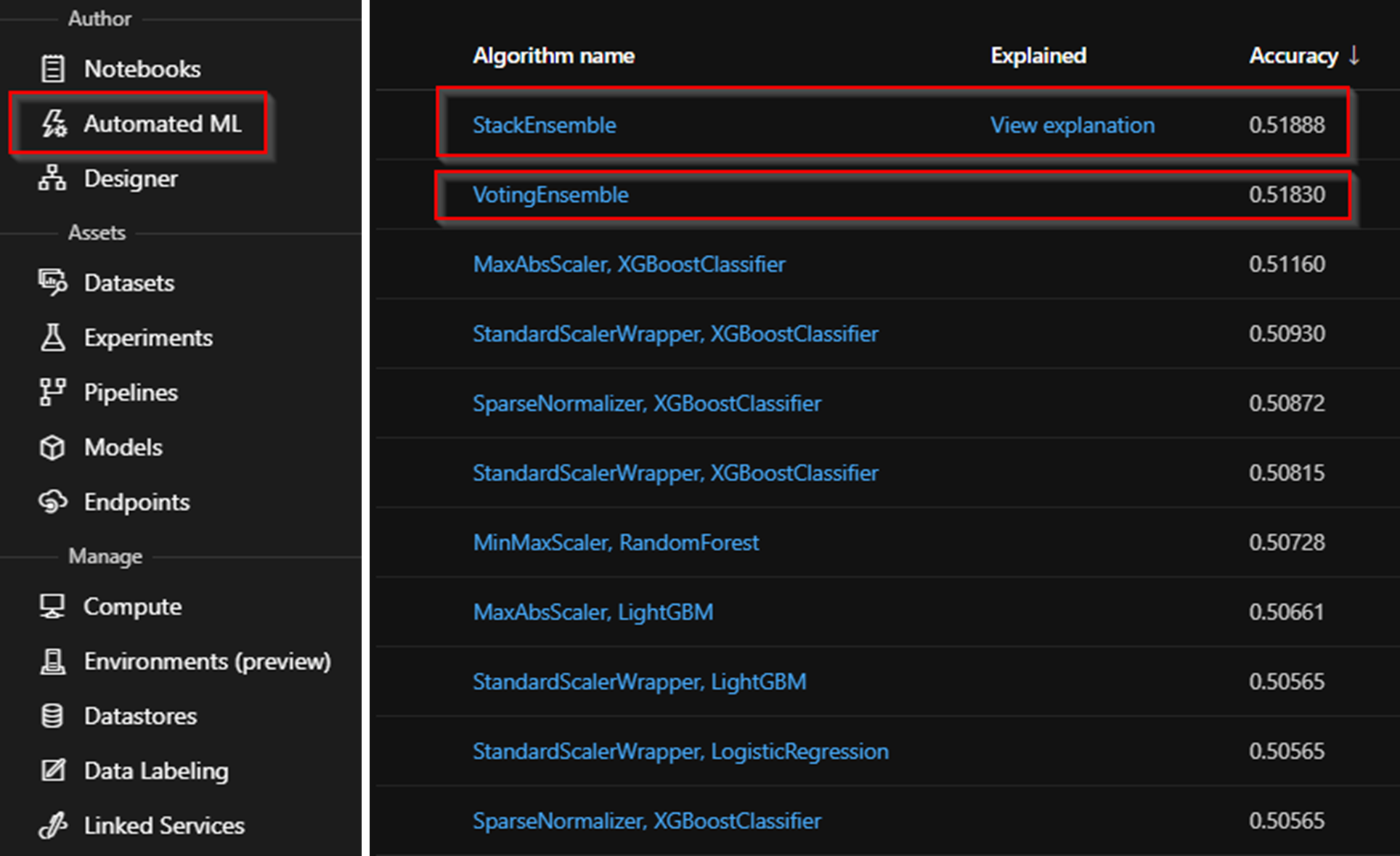
Conclusions
Having tried two different approaches, the question is: which one performs best? And more importantly, can the models beat humans? The final verdict on this will be after the final on July 11th, but we can already say that both models compete in the upper part of the competition in our company. In a later post we will show the final results.
Both teams enjoyed the challenge. Azure ML proved to be a productive environment where it is possible to quickly produce results, even if you are not an AI expert. In future posts we will take up further questions: How can the productivity be enhanced for power users and for teams? How can this be integrated in a production environment?
But for now, let’s wait for the UEFA 2021 final. Enjoy the game!
Subscribe to our RSS feed