SRE blends the principles of software engineering and operations to ensure reliable and efficient systems and services. This blog post explores the core principles and benefits of Site Reliability Engineering, highlighting its role in empowering organizations to deliver exceptional user experiences.
Defining Site Reliability Engineering
Site Reliability Engineering, originally introduced by Google, encompasses an approach to managing complex systems that prioritizes reliability, scalability, and maintainability. SRE teams bridge the gap between development and operations, emphasizing collaboration and automation to enhance system stability.
Core Principles
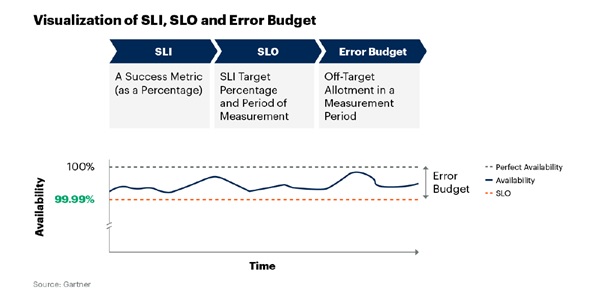
- Service Level Objectives (SLOs): SRE establishes measurable targets, known as Service Level Objectives (SLOs), for the performance and availability of a service. These objectives facilitate shared understanding between development and operations teams, fostering accountability and continuous improvement.
- Error Budgets: SRE introduces the concept of error budgets, quantifying the permissible downtime or service disruptions. This approach encourages innovation and agility by allowing developers to release new features and improvements without compromising reliability. When error budgets are exceeded, the focus is shifted towards reliability and proactive incident management.
- Monitoring and Alerting: Proactive monitoring and alerting are fundamental aspects of Site Reliability Engineering (SRE) that play a vital role in ensuring the reliability and performance of systems and services. Rather than reacting to incidents after they occur, proactive monitoring focuses on detecting potential issues before they impact users.
- Automation: Automation serves as a cornerstone of SRE. By automating repetitive tasks, SRE teams reclaim valuable time to focus on strategic initiatives and proactive maintenance, ensuring robust and resilient systems.
- Blameless RCAs: Blameless Root Cause Analyses (RCAs) are crucial in IT operations as they foster a culture of continuous improvement and learning. By eliminating the blame game, blameless RCAs encourage teams to focus on understanding the underlying causes of incidents and failures. This approach allows for open discussions, enabling us to identify system issues, implement effective remediation strategies and prevent similar incidents from occurring in the future.
Benefits of Site Reliability Engineering
- Improved Reliability: SRE’s focus on reliability minimizes outages and service disruptions, leading to increased customer satisfaction. Proactive risk identification and mitigation enable businesses to maintain a competitive edge.
- Efficient Scaling: SRE practices empower organizations to scale their systems seamlessly. Leveraging automation and monitoring, SRE teams gain insights into performance patterns and capacity needs, enabling companies to meet demand spikes without compromising reliability.
- Collaboration and Culture: SRE fosters collaboration between development and operations teams, dismantling silos and promoting shared responsibility. The culture of blameless postmortems encourages learning from failures and facilitates continuous improvement.
- Cost Optimization: SRE teams contribute to cost optimization by identifying and eliminating waste, optimizing resource utilization, and automating processes. This approach leads to improved cost management while maintaining highly reliable systems.
Conclusion
Site Reliability Engineering represents a transformative approach that empowers organizations to deliver robust and reliable digital services. By blending software engineering principles with operations expertise, SRE enables businesses to achieve high availability, efficient scaling, and cost optimization. By embracing SRE principles and fostering a culture of collaboration and automation, organizations can harness the power of reliability and provide exceptional user experiences in today’s demanding and ever-changing digital landscape.
Subscribe to our RSS feed