ITPROceed took place at Utopolis in Mechelen. A nice venue! Parking in front of the building and a working wifi connection immediately set the pace for a professional conference. There were 20 sessions in total (5 tracks).
Keynote: Microsoft Platform State-of-the-union: Today and Beyond By Scott Klein
Scott Klein kicked off the day with the keynote and gave us a nice state-of-the-union.
Scott explained us once the many advantages of using the cloud and compared it with the old days.
A big advantage is the faster delivery of features, where in the past it could take 3/5 years to deliver a feature through service packs or new versions of software.
Why Microsoft puts Cloud first:
- Speed
- Agility
- Proven
- Feedback
Next to that Scott showed us several new features, SQL Server 2016, Azure SQL Data Warehouse, PolyBase, Data Lake, Windows 10,…
The world is changing for IT Professionals, this means lot’s of changes but also a lot of opportunities!
Are you rolling your environments lights-out and hands-free? by Nick Trogh
Nick gave us a lot of demo’s and showed us how we could spin up new application environment in a reliable and repeatable process. In this session we looked into tools such as Docker, Chef and Puppet and how you can leverage them in your day-to-day activities.

Demystifying PowerBI
Speaker – Koen Verbeeck
Koen gave us a short BI history lesson whereafter he illustrated what each tool is capable of, when you should use it and where you can use it. To wrap up he showed the audience what Power BI v2 (Preview) looks like and how easy it is to use. Great introduction session to (Power) BI!
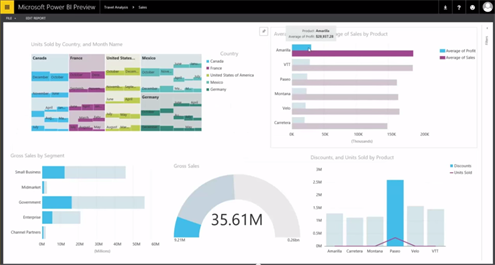
If you’re interested in Power BI v2, you can start here.
Data Platform & Internet of Things: Optimal Azure Database Development by Karel Coenye
In this session Karel told us about several techniques to optimize databases in Azure to get the most out of them and reducing the cost.
With Azure SQL databases you need to think outside the box and optimise with following principle:

Cross premise connectivity with Microsoft Azure & Windows Server by Rasmus Hald
Running everything in the cloud in the year 2015 is very optimistic, often several systems are still running on premise and have not been migrated already to the cloud. Network connectivity between the cloud and on premise is necessary!
Within Codit we already have experience with Azure networking, it was very nice to follow the session to get more tips and tricks from the field.
Rasmus covered four topics:
1. How Windows Server & Microsoft Azure can be used to extend your existing datacenter.
2. How to use existing 3rd party firewalls to connect to Azure.
3. The new Azure ExpressRoute offering.
4. Windows Azure Pack.
Big Data & Data Lake
Speaker – Scott Klein
SQL Scott was back for more, this time on BIG data! He kicked off with an introduction of how many data was processed to calculate the space trip for Neil Armstrong to the moon and how the amounts of data have evolved.
Bigger amounts of data means we need to be able to store them as good & efficient as possible but also be able to work with that data. In some cases plain old databases are not good enough anymore – That’s where Hadoop comes in.

The Hadoop ecosystem allows us to store big amounts of data across data nodes and where we can use technologies such as Pig, Hive, Sqoop and others to process those big amounts of data.

As we start storing more and more data Microsoft started delivering Hadoop clusters in Azure called HDInsights which is based on the Hortonworks Data Platform. If you want to know more about HDInsight, have a look here.

Process big data obviously requires the big data itself, during Scott’s talk he also talked about Azure Data Lake which was announced at //BUILD/ this year. There are several scenarios where you can benefit from Azure Data Lake – It’s built to store your data without any limitation, whether it is size, type or whatsoever, in its raw format.
In the slide below you can see how you can use Azure Data Lake in an IoT scenario.

Just to clarify – Data Lake is not something Microsoft has invented, it’s a well known concept in the Data-space that is kinda the contrary of Data Warehousing. If you want to learn more about Data Lake or the relation with Data Warehousing, read Martin Fowlers vision on it.
Scott wrapped up his session with a demo on how you can spin up an Azure HDInsight cluster. After that he used that cluster to run a Hive query on your big files stored in an Azure Storage account as blobs.
Great introduction session to big data on Azure.
Securing sensitive data with Azure Key Vault by Tom Kerkhove
Speaker – Tom Kerkhove
In the closing session Tom introduced us the concepts of Microsoft Azure Key Vault that allows us to securely store keys, credentials and other secrets in the cloud.

Why you should use Azure Key Vault:
- Store sensitve data in hardware security modules (HSM)
- Gives back control to the customer
- Full control over lifecycle and audit logs
- Management of keys
- Removes responsibility from developers
- Secure storage for passwords, keys and certificates
- Protect production data
Subscribe to our RSS feed